
The landscape of software engineering is currently undergoing its most radical transformation since the advent of high-level programming languages. At the heart of this shift is the phenomenon of "vibe coding"—a paradigm where developers leverage generative artificial intelligence to translate plain-language intent into functional blocks of code at unprecedented speeds. However, this velocity has introduced a significant secondary crisis: a deluge of pull requests that human engineers can no longer vet with the necessary rigor. To address this emerging bottleneck, Anthropic has unveiled "Code Review," a sophisticated AI-driven diagnostic tool integrated into the Claude Code ecosystem designed to act as an automated peer reviewer.
The release of Code Review marks a critical evolution in the role of Large Language Models (LLMs) within the DevOps lifecycle. Traditionally, AI tools were viewed primarily as "authors"—engines of creation that could generate boilerplate, suggest functions, or autocomplete lines of code. As these tools matured, the volume of code being produced began to outpace the capacity of senior developers to review it. In modern enterprise environments, code quality is maintained through a process of peer feedback and pull requests (PRs), where changes are scrutinized for bugs, security vulnerabilities, and architectural consistency before being merged into a primary codebase. When AI accelerates the "writing" phase by a factor of ten, the "review" phase becomes a catastrophic point of congestion.
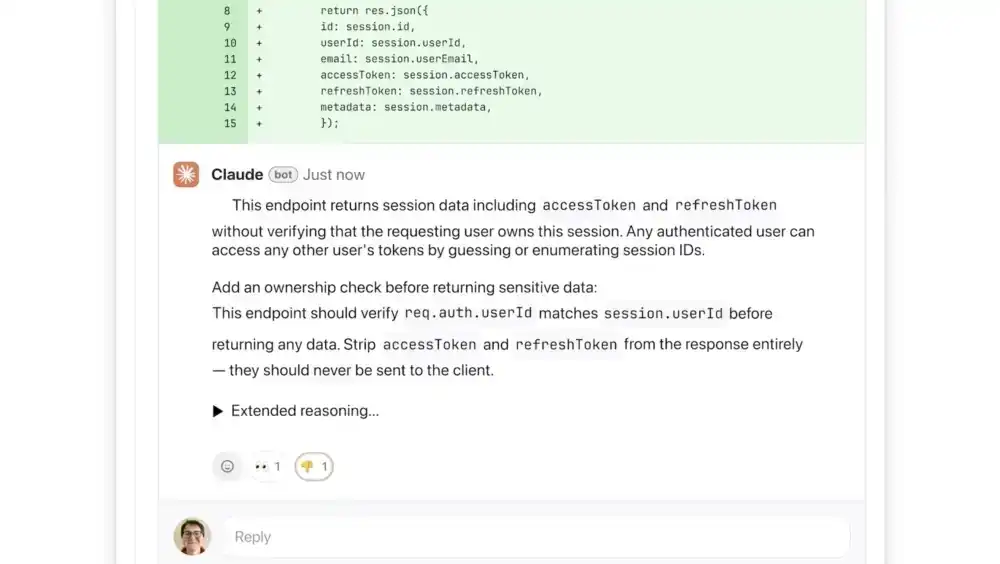
Anthropic’s Code Review, launched initially as a research preview for Claude for Teams and Claude for Enterprise, seeks to resolve this imbalance. By integrating directly with version control platforms like GitHub, the tool automatically analyzes incoming pull requests and provides granular, actionable commentary. Unlike basic linters or static analysis tools that focus on syntax and formatting, Code Review is engineered to detect deep logical inconsistencies—the "silent killers" of software stability that often elude automated checks.
The Mechanics of Multi-Agent Oversight
The technical architecture of Code Review distinguishes it from previous attempts at automated code validation. Rather than relying on a single pass from a general-purpose model, the system utilizes a multi-agent framework. This approach involves several specialized AI agents working in parallel, each tasked with examining the codebase through a specific lens. One agent might focus on data flow and state management, while another evaluates the integration of new functions with existing modules.
Once these specialized agents complete their individual assessments, a "summarizer" or "aggregator" agent synthesizes the findings. This final layer is responsible for removing redundant observations, ranking issues by their potential impact, and ensuring that the feedback provided to the human developer is concise and relevant. This hierarchical processing is intended to mimic the workflow of a high-functioning engineering team, where different specialists contribute their expertise before a lead architect makes a final determination.
To improve clarity for human supervisors, the tool employs a color-coded severity system. Issues highlighted in red indicate high-priority logical errors or critical failures that could lead to system crashes or data corruption. Yellow flags signify potential "code smells" or optimizations that, while not immediately destructive, warrant human attention. A unique purple designation is reserved for issues linked to pre-existing technical debt or historical bugs that the new code might be inadvertently exacerbating.
Addressing the "Vibe Coding" Fallout
The term "vibe coding" has emerged as a double-edged sword within the tech industry. While it democratizes software creation and allows for rapid prototyping, it often results in code that is "correct enough" to run but lacks the structural integrity required for long-term maintenance. AI-generated code can be verbose, redundant, or reliant on deprecated libraries—flaws that are difficult to spot during a cursory glance at a large PR.
Cat Wu, Anthropic’s Head of Product, has noted that the market demand for an automated reviewer was driven by the success of Claude Code itself. As enterprises adopted AI to speed up feature development, their senior engineers found themselves buried under a mountain of PRs generated by their junior counterparts (and their AI assistants). By focusing strictly on logical errors rather than stylistic preferences, Anthropic aims to reduce "developer fatigue." Software engineers are notoriously sensitive to automated tools that "cry wolf" or offer pedantic advice on indentation and naming conventions. By prioritizing high-stakes logic, Code Review attempts to earn the trust of the developer community as a meaningful collaborator rather than a nuisance.
The Economic and Strategic Context
The launch of Code Review comes at a time of significant financial momentum and legal complexity for Anthropic. The company’s enterprise business has seen a fourfold increase in subscriptions since the beginning of the year, with Claude Code generating a run-rate revenue exceeding $2.5 billion. High-profile clients such as Uber, Salesforce, and Accenture represent the vanguard of this adoption, signaling that the "AI-first" development model is no longer a niche experiment but a standard operating procedure for the Fortune 500.
However, this growth is set against a backdrop of tension with federal regulators. Anthropic recently initiated legal action against the Department of Defense (DoD) following the agency’s designation of the company as a "supply chain risk." This designation is particularly impactful for a company seeking to provide the underlying infrastructure for American software development. The introduction of robust, transparent, and security-focused tools like Code Review may serve as a strategic rebuttal to these concerns. By proving that AI can be used to improve the security and reliability of the software supply chain rather than just inflating it with unverified code, Anthropic is positioning itself as a guardian of software integrity.
Pricing and the Value of Quality
The economics of Code Review reflect its positioning as a premium enterprise utility. Built on a token-based pricing model, a single review is estimated to cost between $15 and $25, depending on the complexity of the code and the breadth of the codebase being analyzed. While this may seem steep compared to traditional static analysis software, it is a fraction of the cost of an hour of a senior developer’s time.
In the context of a large-scale enterprise, the cost of a single bug reaching production can range from thousands to millions of dollars in lost revenue, remediation efforts, and reputational damage. From this perspective, a $20 "insurance policy" on every pull request represents a compelling return on investment. Furthermore, the tool’s ability to provide step-by-step reasoning for its suggestions serves an educational purpose, potentially upskilling junior developers by showing them exactly where their logic faltered.
Security and the Path Forward
While Code Review offers a "light" security analysis, it is designed to work in tandem with the more specialized Claude Code Security module. Recent benchmarks have shown that Claude-based tools are capable of identifying complex vulnerabilities in major open-source projects, such as the Firefox browser, where it successfully flagged over 20 vulnerabilities in a two-week period.
The integration of these capabilities into a daily workflow suggests a future where the "security audit" is not a separate phase of development but a continuous, real-time process. As engineering leads gain the ability to customize additional checks based on internal best practices, the AI becomes a repository for a company’s institutional knowledge, ensuring that every line of code adheres to the specific safety standards of the organization.
The Future of the Developer Role
As Anthropic and its competitors continue to build out the "AI agent" ecosystem, the fundamental nature of being a "programmer" is being redefined. We are moving toward an era of "Architectural Oversight," where the human’s primary responsibility is no longer the manual input of syntax, but the curation and validation of system designs.
The "PR bottleneck" is the first of many such friction points that will emerge as AI agents take over the heavy lifting of execution. Tools like Code Review are essential bridges in this transition. They provide the necessary guardrails to ensure that as we accelerate toward a future of AI-generated software, we do not sacrifice the stability and security that form the foundation of our digital economy. For enterprises, the promise is clear: the ability to build faster than ever before, but with a level of precision that was previously unattainable at scale.
