
The landscape of large language models (LLMs) is undergoing a period of significant, and sometimes jarring, realignment. Recent strategic decisions by major players, particularly concerning data governance, ethical alignment, and high-profile enterprise contracts—such as OpenAI’s noted partnership with the US Department of Defense—have catalyzed a noticeable user migration. For many professionals and power users who have deeply integrated tools like ChatGPT into their daily workflows, these shifts necessitate a pragmatic reassessment of platform allegiance. This is not merely a matter of switching chatbots; it involves porting established digital expertise and contextual memory built up over months or years of interaction. My personal decision to transition away from OpenAI’s ecosystem was precipitated by a confluence of these external corporate developments and an increasing internal scrutiny regarding long-term data stewardship and model safety protocols.
Deciding to sever ties with a platform that has become a foundational element of one’s productivity is a non-trivial undertaking. It demands meticulous planning to ensure that the accumulated value—the specialized knowledge, preferred conversational styles, and proprietary information threaded through thousands of prompts—is not lost in the transition. This analysis outlines a rigorous, five-stage protocol for users contemplating a similar migration, applicable whether the destination is Anthropic’s Claude, Google’s Gemini, or another emerging contender. This process is designed to maximize data preservation and minimize the inevitable friction of onboarding a new AI partner.
Phase 1: Establishing a Comprehensive Data Archive
The absolute prerequisite for any platform migration is the secure, complete extraction of historical interaction data. While the process provided by OpenAI for data export is functional, it is far from seamless, especially for users with extensive interaction logs. This initial step must be approached with an expectation of potential turbulence and redundancy checks.
The formal mechanism involves navigating to the account settings and initiating the data export request. For power users, the time latency for this process can be significant, often extending beyond 48 hours, contingent on the sheer volume of stored conversations. It is crucial to understand that this export is not instantaneous; it is a queued backend process.
A key technical observation from repeated attempts is the fragility of the export archive when dealing with exceptionally large datasets. Early exports have been known to suffer from corruption, resulting in non-rendering or garbled HTML files within the resulting ZIP package. This necessitates a robust verification loop: if the initial archive fails to render intelligibly across standard browsers (e.g., exhibiting rendering issues in Chrome but functioning correctly in Firefox), the export request must be immediately re-initiated. This redundancy ensures that the user retains the best possible snapshot of their historical usage, which is invaluable for knowledge transfer. The HTML output, while navigable, serves primarily as a raw historical record rather than a directly transferable knowledge base.
Phase 2: Deconstructing and Structuring Contextual Memory
The true value embedded within an LLM relationship often resides not in the specific questions asked, but in the nuanced understanding the model develops regarding the user’s specific domain, tone, and operational context. Simply exporting raw chat logs fails to capture this synthesized expertise effectively. Therefore, a critical intermediate step is the systematic deconstruction of this learned personalization into a transferable knowledge packet.
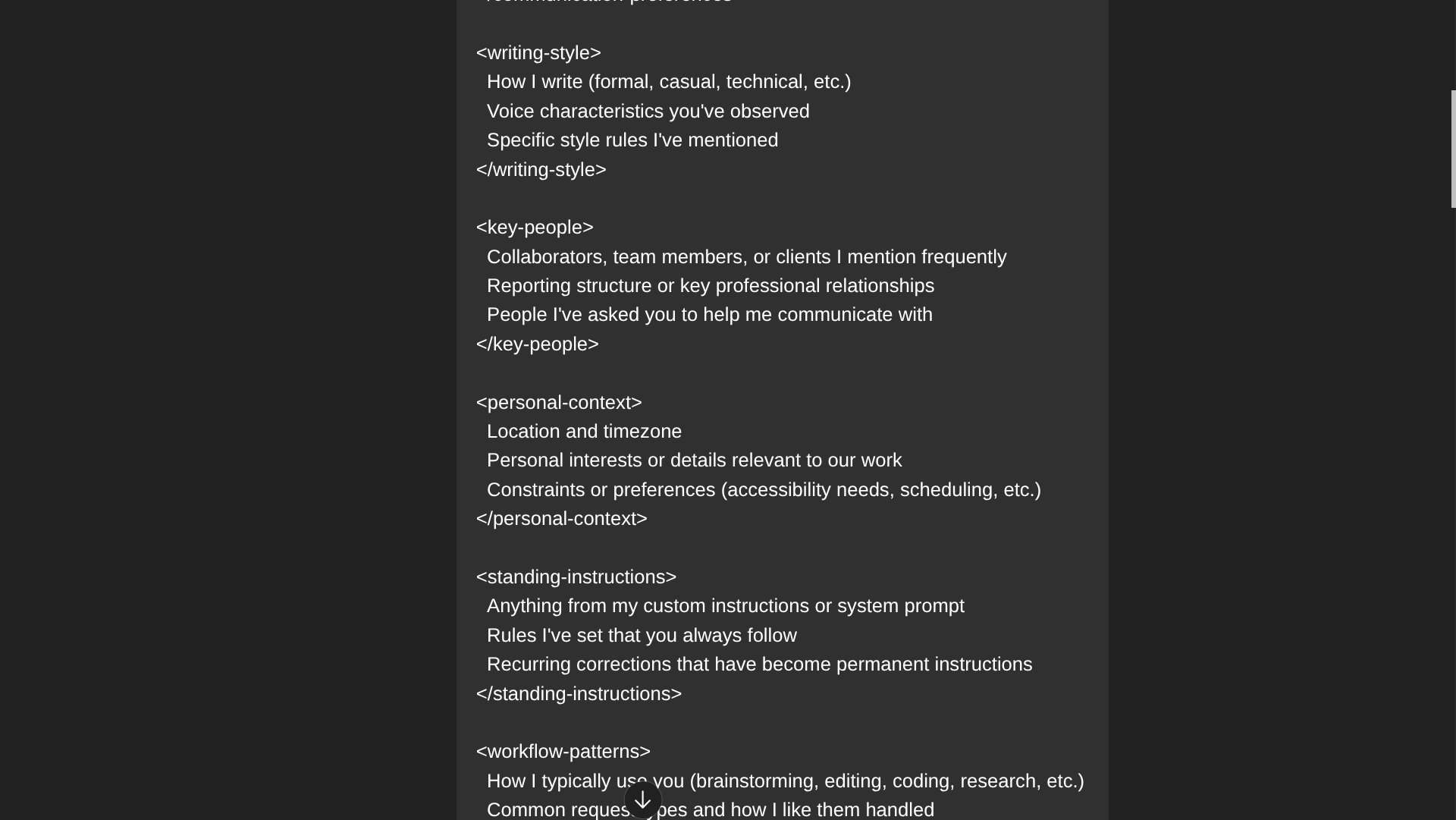
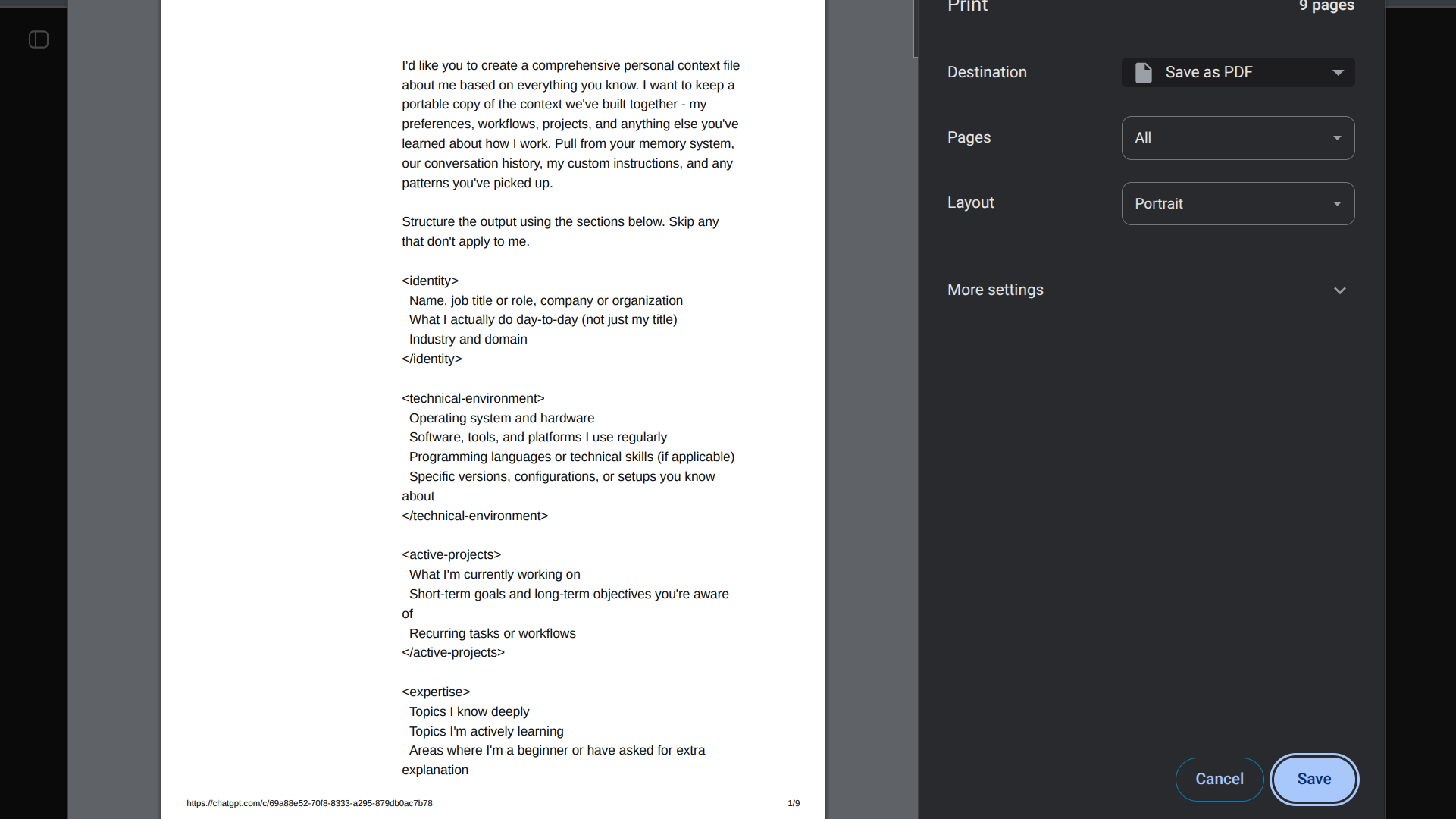
While competitive platforms like Claude offer straightforward, pre-built import prompts, these often generalize the user profile. To achieve a higher fidelity transfer, a more granular, proprietary method is advisable. This involves leveraging a carefully crafted meta-prompt—one designed not to signal departure but to elicit a comprehensive self-summary of the user relationship from the existing model. This prompt should segment the required output into distinct functional categories:
- Writing Style and Idiosyncrasies: Detailed linguistic patterns, preferred jargon, formality levels, and structural preferences.
- Key Entities and Contextual Anchors: Names, project identifiers, recurring terminology, and established factual constraints relevant to the user’s domain.
- Workflow Patterns: Recurring tasks, typical decision-making frameworks, and preferred iterative processes (e.g., drafting, reviewing, summarizing).
The output from this advanced prompting should be collated into a master document, such as a dedicated Google Doc. This synthesis step often reveals redundancies present in the raw chat history but forces a structured articulation of the model’s implicit learning.
The subsequent transfer of this structured knowledge to the new platform is multifaceted. For platforms like Claude, a dedicated import utility can ingest this document directly. For others, the process involves initiating a new, high-priority conversation, explicitly framing the pasted, synthesized knowledge as the foundational "system prompt" or "memory injection" for all subsequent interactions. This ensures the new LLM begins its relationship with a deeply informed understanding of the user’s operational requirements, bypassing the typical ramp-up period.
Phase 3: Archiving Critical Project Threads via Document Export
Beyond the generalized personalization profile, specific, long-running projects or complex threads warrant preservation in a format optimized for easy reference rather than bulk re-ingestion. The raw HTML export is unwieldy for quickly locating a specific decision point or finalized output from a complex chain of reasoning.
A more practical approach involves targeted archival using standard document formats. The "Print to PDF" function (accessible via Ctrl+P or the browser’s print dialogue) proves highly effective here. By printing critical conversation threads directly to PDF, the user creates discrete, searchable, and portable reference files. These PDFs serve as immediate context documents that can be uploaded directly into the context window of the new LLM when resuming a project.
This method offers significant advantages over relying solely on the bulk export. It provides chronological integrity for specific tasks and is significantly easier for the human user to reference. While the new LLM cannot learn the entire chat history via this method, it can process the specific context of the uploaded document, allowing the user to instantly pivot back into a complex task flow. This bridges the gap between historical record-keeping and active workflow resumption.
Industry Implications and the Shifting Trust Paradigm
The willingness of experienced users to undertake this complex migration highlights a fundamental shift in the relationship between technology providers and their most engaged clientele. Historically, data lock-in was a significant barrier to platform switching, especially in proprietary enterprise software. However, the nascent, high-stakes nature of generative AI has introduced a new variable: trust.
The industry is currently wrestling with the tension between rapid commercialization (represented by lucrative defense contracts or aggressive data monetization strategies) and the ethical imperatives championed by some competitors, such as Anthropic’s foundational commitment to safety guardrails. When a primary AI provider appears to compromise on these perceived ethical boundaries, the user base, particularly those dealing with sensitive or proprietary information, is forced to re-evaluate the risk calculus.
This exodus, even if small in absolute numbers initially, carries significant symbolic weight. It signals that for a segment of the market, algorithmic alignment and corporate ethics now outweigh sheer performance metrics or incumbency advantage. This places immense pressure on platforms like Google (with Gemini) and Anthropic (with Claude) to not only match the performance ceilings of leaders but also to demonstrably uphold superior data privacy and ethical development standards. The market is demanding transparency, and procedural steps like data export become tangible evidence of a provider’s commitment to user agency.
Expert Analysis: The Friction of Contextual Transfer
From a cognitive load perspective, transferring expertise to a new LLM is analogous to retraining an apprentice. While the raw foundational knowledge (the underlying language models) might be similar, the fine-tuning unique to the previous relationship must be re-established.
The process detailed in Phase 2—the structured prompt engineering to extract and import personalization—is an advanced technique that minimizes this "re-training tax." The prompt acts as a high-density knowledge transfer protocol. However, experts note that the integration of this external knowledge into the new model’s persistent memory (or context buffer) is often imperfect. New models may interpret generalized style guides differently than the originating model. Continuous iterative prompting in the early days on the new platform is necessary to "reinforce" the imported context.
Furthermore, the technical hurdle of data export fragility (Phase 1) reveals an immature infrastructure for data portability within the AI sector. Unlike established cloud services where APIs facilitate smooth migration of user profiles and settings, current LLM data management often relies on cumbersome, one-off export mechanisms that are not engineered for seamless interoperability. This deficiency will become a major competitive battleground; the platform that perfects effortless, comprehensive data migration will gain a significant advantage in attracting disillusioned users from incumbent systems.
Future Impact and the Trend Toward Decentralization
The current reliance on centralized, proprietary platforms for foundational AI capabilities is inherently fragile, as evidenced by the friction experienced during these migrations. The future trajectory of advanced AI usage is likely to involve a push toward greater decentralization and user sovereignty over models and data.
We can anticipate several key trends emerging from this user sentiment:
- Enhanced Portability Standards: Industry consortia or regulatory bodies may push for standardized data exchange formats for LLM interactions, similar to what exists for email or contact lists, thereby reducing the necessity of the complicated manual steps outlined here.
- Local and Federated Models: Increasing interest in running smaller, highly capable models locally (on-device or private cloud infrastructure) will offer users absolute data control, bypassing the trust issues associated with third-party storage and governance entirely.
- AI Brokerage Layers: Software layers that sit between the user and multiple LLM backends will become more prevalent. These brokers could manage data synchronization, contextual transfer, and subscription billing across various models, allowing users to leverage the best model for a specific task without having to manually switch accounts or re-import profiles each time.
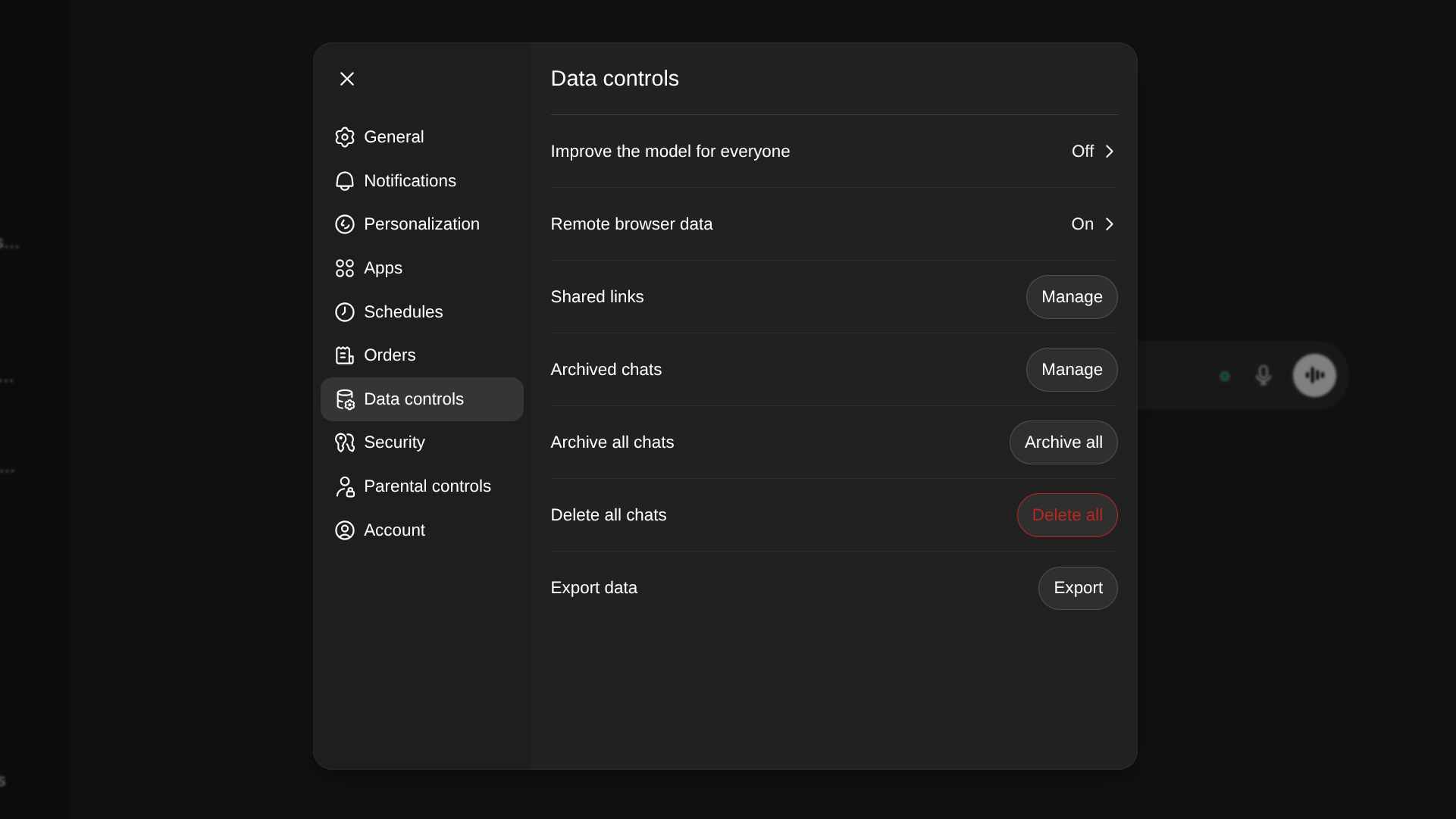
Finalizing the Severance: Data Deletion and Integration Revocation
The final stages of departure move from preservation to complete severance, which must be handled with equivalent diligence to ensure digital hygiene.
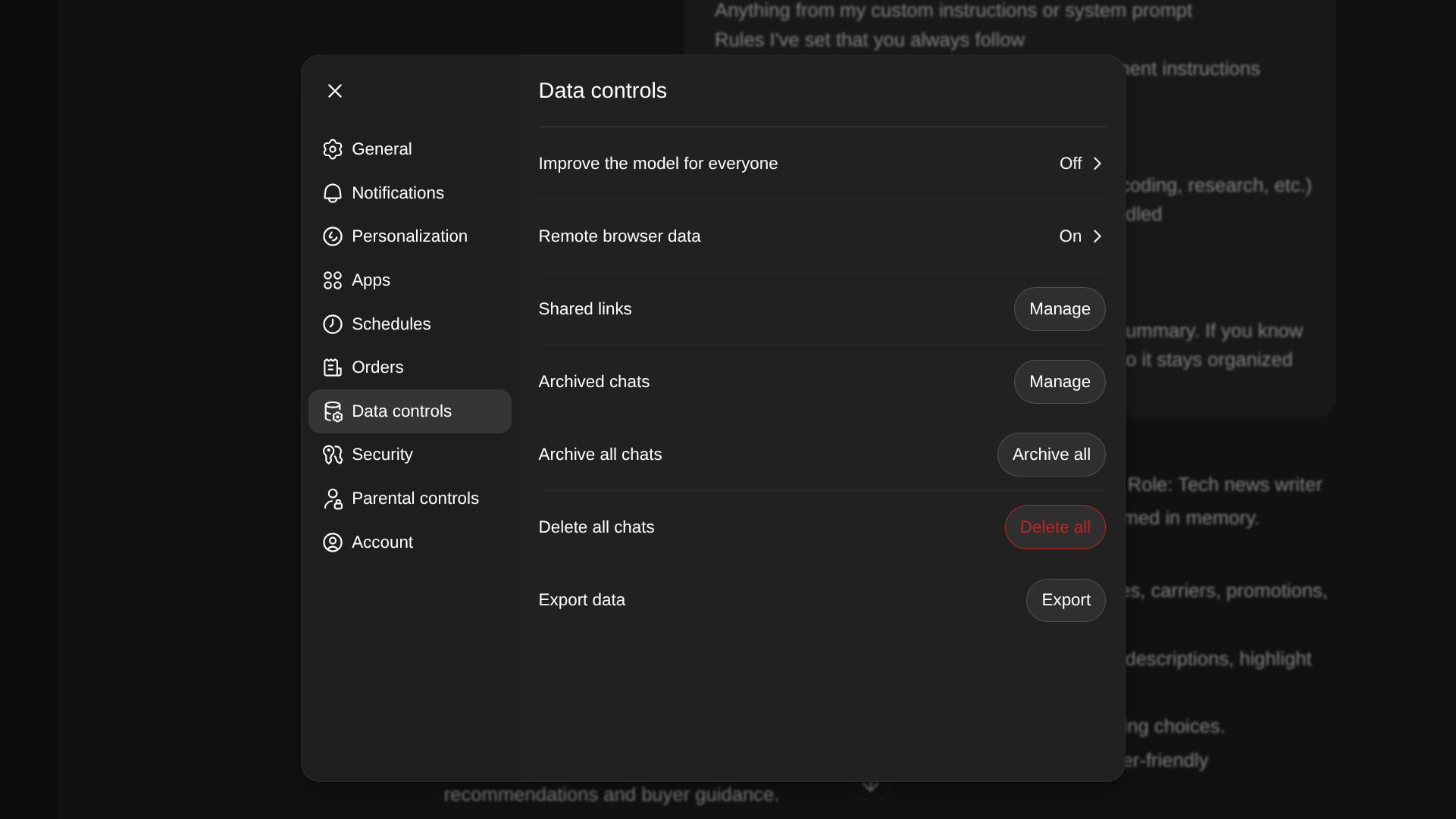
Before initiating the final deletion, absolute confirmation of the successful archival of data (Phases 1-3) is paramount. Once confirmed, the user should navigate to the platform’s Data Controls settings and execute the comprehensive "Delete All Chats" function. It is vital to internalize OpenAI’s stated retention policy: complete data removal from active servers can take up to 30 days, and residual, de-identified data may persist for security or legal compliance reasons. This is a critical caveat for users whose primary motivation for leaving is sensitive data exposure.
For the most absolute termination, an optional, but highly recommended, secondary action involves visiting the dedicated privacy portal (privacy.openai.com in this context) and submitting a formal request for full account termination, distinct from simply cancelling the subscription. This step leverages broader consumer privacy frameworks available in many jurisdictions, aiming for a more definitive shuttering of the user record, provided subscription cancellation has already been processed.
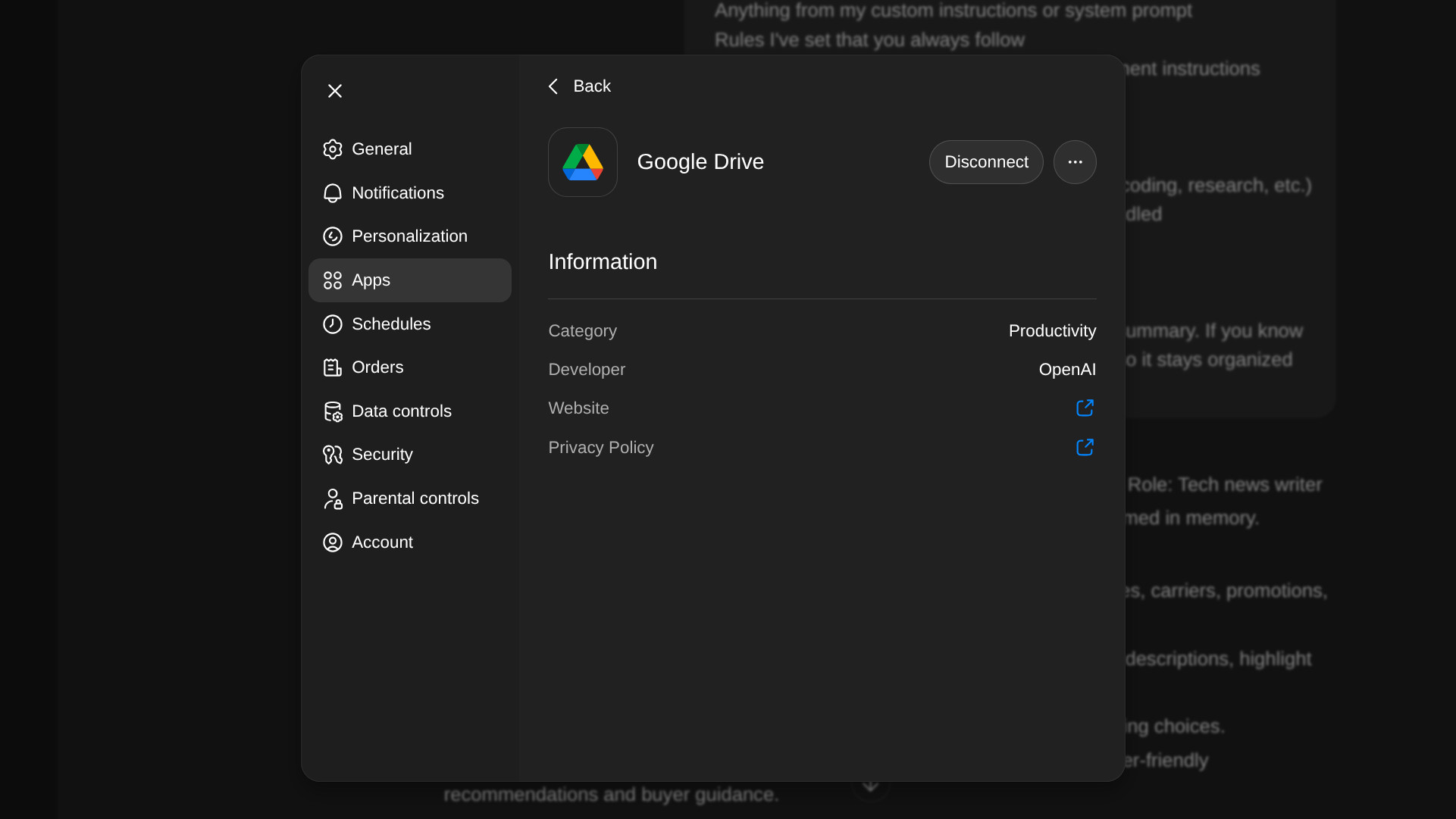
The final administrative step involves auditing and revoking external connections. Any third-party applications, cloud storage services (like Google Drive), or developer integrations that were granted access tokens to the ChatGPT environment must have that authorization explicitly revoked within the settings panel dedicated to Apps or Integrations. While token expiration usually renders these defunct upon account closure, proactively revoking access closes any potential lingering vulnerability vector.
With the subscription cancelled, data secured, and access points purged, the user is prepared to fully embrace a new technological chapter. The choice of the successor platform remains highly individual. While models like Claude offer a compelling focus on safety and extensive context windows, Google’s Gemini ecosystem offers deep integration advantages, particularly for users heavily invested in the Android and broader Google Workspace environments. The migration process itself serves as a powerful reminder that in the rapidly evolving AI ecosystem, user agency—the ability to control and move one’s digital history—is becoming the most valuable feature of all.
