

The architecture of modern cloud infrastructure, particularly environments spanning multiple AWS regions and services, is inherently complex and often characterized by sprawling, ephemeral resources. When critical alerts surface—be it an alarming spike in EC2 CPU utilization, an unexpected S3 bucket policy modification, or service degradation masked by generic monitoring data—the initial response phase frequently devolves into a time-consuming, fragmented scavenger hunt. Incident responders are forced into a cycle of context switching: tearing themselves away from their primary incident tracking system (like a ticketing platform), navigating the labyrinthine AWS Management Console, grappling with Multi-Factor Authentication (MFA) delays, and painstakingly recalling the precise, often verbose, AWS Command Line Interface (CLI) syntax required to extract the verifiable truth about the failing resource.
This relentless cognitive load, often termed the "context-switching tax," exacts a significant toll. It directly inflates Mean Time to Resolution (MTTR), a crucial metric for business continuity and customer satisfaction. More insidiously, this repetitive, low-value data retrieval process leads to analyst fatigue and burnout, diverting skilled personnel away from complex problem-solving and remediation toward mundane, rote data collection.
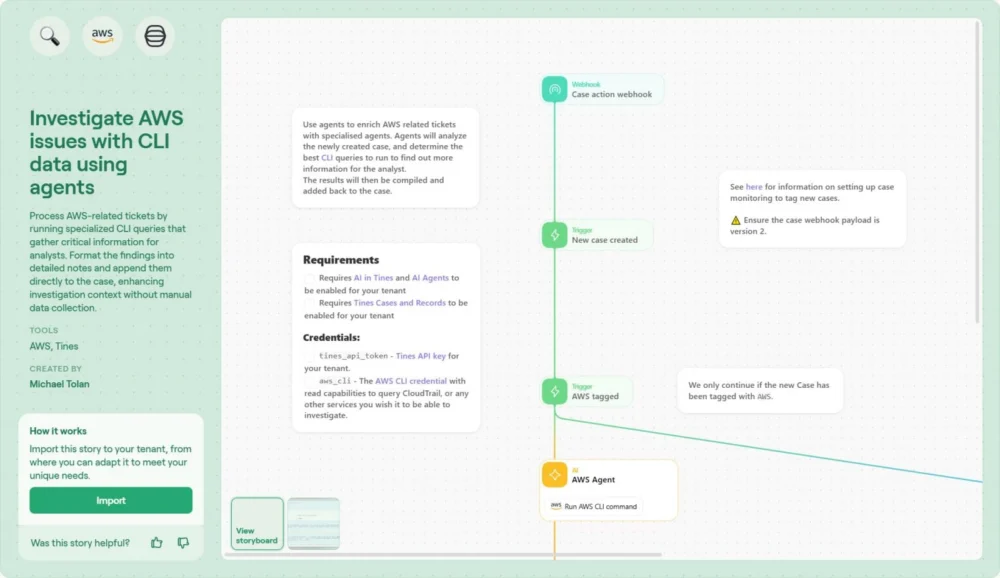
This detailed examination focuses on a sophisticated, pre-configured automation blueprint—specifically, a Tines workflow designed to "Investigate AWS issues with CLI data using agents." This solution systemically eliminates the manual data-gathering bottleneck by securely embedding the necessary diagnostic CLI execution capabilities directly within the incident management workflow, thereby collapsing the investigation timeline.
The Pervasive "Context Gap": A Barrier to Scalable Response
In enterprise settings leveraging hyperscale cloud providers, a fundamental disconnect often persists between the operational tracking layer and the technical data layer. Work artifacts reside in IT Service Management (ITSM) platforms or project management tools (Jira, ServiceNow), while the authoritative evidence resides deep within cloud provider APIs and logs (AWS, Azure, GCP).
A seemingly straightforward incident triage often necessitates a multi-step manual choreography:
- Alert Ingestion: An alarm fires in a monitoring tool (e.g., CloudWatch, Datadog) referencing a resource ID.
- Context Transfer: The analyst manually copies the resource ID, service type, and time frame.
- Authentication Gauntlet: The analyst logs into the AWS console, potentially navigating multiple accounts or roles, and clears MFA challenges.
- Tool Switching: The analyst opens a local terminal or an AWS CloudShell session.
- Syntax Recall: The analyst must accurately construct the correct
aws <service> describe-resource --resource-id <id>command, remembering region-specific flags and output formats. - Data Interpretation: The analyst sifts through dense, often unformatted JSON output to find the critical piece of information—a specific tag, an attached security group, or the instance status code.
- Documentation: Finally, the analyst copies the relevant findings back into the original ticket for documentation and handoff.
This entire process, repeated dozens or hundreds of times daily, is anathema to operational scalability. As evidenced in prior industry reports, including a recent case study involving a high-volume crowdfunding platform, the transition from spreadsheet-driven, manual remediation steps to robust workflow orchestration resulted in a staggering 83% reduction in unpatched vulnerabilities within a mere quarter. The core operational mandate derived from such successes is clear: automation must absorb the mechanical drudgery, allowing human expertise to concentrate solely on analysis and high-impact remediation.
The Hidden Financial and Operational Drag
The cost of maintaining manual IT infrastructure processes extends beyond analyst frustration. It manifests as delayed service restoration, increased risk exposure due to slow patching cycles, and inflated operational expenditure associated with inefficient staffing ratios. Running critical cloud operations without comprehensive automation forces organizations into a reactive posture, constantly firefighting instead of proactively optimizing. Modern IT Operations and Security teams require predictable, repeatable execution paths that leverage existing toolsets but eliminate human latency.
The Agent-Centric Paradigm: Bringing the CLI to the Analyst
The proposed solution leverages a dedicated workflow pattern that decisively bridges the artifact gap between the incident ticket and the live cloud environment. This is achieved through the strategic deployment of Tines agents—lightweight, secure execution environments capable of securely interfacing with AWS using strictly scoped credentials. The central innovation here is reversing the traditional flow: rather than the analyst navigating to the cloud environment, the necessary diagnostic commands are executed remotely, and the results are delivered directly to the analyst’s workspace.
The operational sequence of this automated investigation pathway is highly structured and inherently secure:
-
Workflow Initiation (The Trigger): The process begins not with manual intervention, but typically upon the creation of a new incident ticket referencing an affected AWS resource ID, or automatically when a high-fidelity alert is ingested from a monitoring source (e.g., a specific anomaly detected by CloudWatch or a Security Hub finding).
-
Secure Agent Intermediation: Crucially, the Tines platform itself does not require broad, over-privileged access tokens to the customer’s AWS account. Instead, the workflow directs a pre-deployed Tines Agent—which resides within a secure, known network perimeter and holds only the minimal required read-only IAM permissions for discovery—to execute the commands. This containment strategy drastically limits the blast radius should credentials be compromised, as the necessary access is localized and ephemeral to the execution context.
-
Context-Aware Command Synthesis: This is where true intelligence surpasses static scripting. The workflow is engineered to dynamically construct the necessary CLI command string based on the contextual data extracted from the initial alert or ticket. For instance, if the alert specifies an EC2 instance failure, the workflow dynamically generates
aws ec2 describe-instances --instance-ids i-xxxxxxxxxxxxx --query 'Reservations[*].Instances[*].[State.Name, SecurityGroups, PublicIpAddress]'. This dynamic construction capability allows the automation to handle varied inputs without requiring the analyst to hardcode dozens of specific command variations. -
AI-Powered Data Transformation and Enrichment: Raw CLI output, frequently delivered as verbose JSON blobs, represents a significant cognitive hurdle for rapid triage. The workflow incorporates powerful data transformation steps, often augmented by integrated Generative AI capabilities. This step parses the raw output, filters noise, and restructures the findings into concise, human-readable formats—such as summary tables or bulleted lists—highlighting only the deviation or the crucial metadata points (e.g., "Security Group Attached: restricted-prod-sg; Public IP: None").
-
Consolidated Case Reporting: The final, enriched findings are automatically appended to the originating Tines Case or pushed directly into the relevant ITSM ticket fields. The analyst viewing the ticket instantly sees the ground truth—the current state, associated network configurations, and metadata—without ever needing to authenticate into AWS or switch tools.
Analytical Deep Dive: The Benefits of Contextual Automation
The integration of agent-driven CLI execution fundamentally reshapes the economics and efficacy of cloud incident response:
- Drastic MTTR Reduction: By automating the 5-10 minute manual data retrieval process into mere seconds of automated execution, the time spent in the "discovery" phase of the incident lifecycle approaches zero. This immediate context allows remediation actions to commence almost instantly.
- Enhanced Security Posture: Limiting the execution environment via specialized agents with least-privilege IAM roles enhances the overall security hygiene. Credentials are managed securely within the orchestration framework, minimizing the surface area for credential harvesting attacks associated with shared console access or widespread CLI configuration.
- Standardization and Auditability: Every investigation follows the exact, defined path, ensuring consistency regardless of which analyst picks up the ticket. Furthermore, the entire sequence of commands executed and the resulting data are immutably logged within the workflow execution history, providing a perfect audit trail for compliance and post-mortem analysis.
- Analyst Skill Optimization: Shifting analysts from data retrieval operators to strategic decision-makers elevates team performance. Their focus moves from what is happening to why it is happening and how to prevent recurrence.
Engineering the Blueprint: Implementation Steps
To deploy this crucial capability, organizations can utilize existing template structures, streamlining the path to operational readiness. This template is designed for rapid deployment rather than bespoke development from scratch.
Step 1: Template Acquisition and Ingestion: Navigate to the Tines Library and locate the specific story template titled "Investigate AWS issues with CLI data using agents." Import this story directly into the operational tenant environment. This immediately populates the canvas with the necessary triggers, action blocks, and data transformation logic.
Step 2: Secure Credential Binding: Establish the secure link to the AWS environment. This involves securely connecting an AWS credential (preferably an IAM Role assumed via a cross-account mechanism or an Access Key pair scoped for read-only access) within the Tines configuration. This step is critical as it authorizes the Agent to communicate with the AWS API endpoints on behalf of the organization.
Step 3: Curating Command Directives: While the template includes a baseline set of essential diagnostic commands (e.g., checking security group ingress/egress, describing IAM policies, checking resource tags), this list must be tailored. Review the most frequent incident types your team handles (e.g., RDS connectivity issues, Lambda errors) and update the agent’s command repository to prioritize the most relevant aws cli calls for those specific scenarios. This targeted approach maximizes the immediate value derived from the automation.
Step 4: Refining the Output Schema: The final presentation layer—the Tines Case or the integrated ITSM ticket field—must be optimized for analyst consumption. Review the pre-configured data mapping blocks. Adjust the structure to ensure that the most actionable intelligence (e.g., "Instance Status: Stopped," "Associated Security Group: Denying All Egress") is prioritized and presented prominently, potentially using conditional formatting based on the severity of the finding.
Step 5: Validation and Operational Handover: Execute the workflow using a controlled, non-production incident scenario (a "dummy ticket" referencing a test resource). Rigorously verify that the agent successfully executes the commands, that the data parsing correctly handles expected edge cases (e.g., missing IPs or empty arrays in the JSON response), and that the final output in the case file is unambiguous and actionable.
Conclusion: Transforming Operational Friction into Strategic Advantage
The persistence of manual data retrieval in the face of sophisticated cloud environments represents a significant vulnerability—a soft spot where human error and latency introduce risk. The transition from reactive, fragmented investigation to proactive, integrated diagnostics is not merely an optimization; it is a prerequisite for scaling modern DevOps and SecOps practices.
By leveraging agent-based execution coupled with intelligent data processing, organizations fundamentally invert the investigative dynamic. The data, once hidden behind authentication barriers and complex syntax, is instantly surfaced within the operational workspace. This immediate contextual awareness empowers security and operations teams to bypass the noise of data collection and immediately engage in high-value activities: root cause analysis, strategic remediation, and proactive hardening. As observed in high-growth technology firms, this shift from managing mundane tasks to mastering intelligent workflows directly translates into a demonstrably superior security posture and operational resilience.
