

A sophisticated exploit, leveraging fundamental differences between how web browsers render content visually and how Artificial Intelligence (AI) models parse underlying code structures, has been uncovered, capable of concealing malicious instructions from leading large language models (LLMs). This novel attack vector exploits the rendering pipeline, specifically targeting custom font handling, to present one set of instructions to a human user while feeding a benign, sanitized version of the webpage to an automated analysis agent.
The core vulnerability lies in the divergence between the Document Object Model (DOM) and the resultant pixel output displayed on a screen. Researchers at LayerX, a firm specializing in browser-based security, successfully demonstrated a proof-of-concept (PoC) where they manipulated font glyphs and cascading style sheets (CSS) to achieve this deceptive dual reality. In essence, the malicious payload is encoded within the HTML structure in a way that AI crawlers—which typically ingest raw, structured text data—interpret as meaningless or safe character sequences. Simultaneously, the browser, utilizing custom font definitions, decodes these sequences into actionable, dangerous commands visible to the unsuspecting user.
The Mechanics of Visual Deception
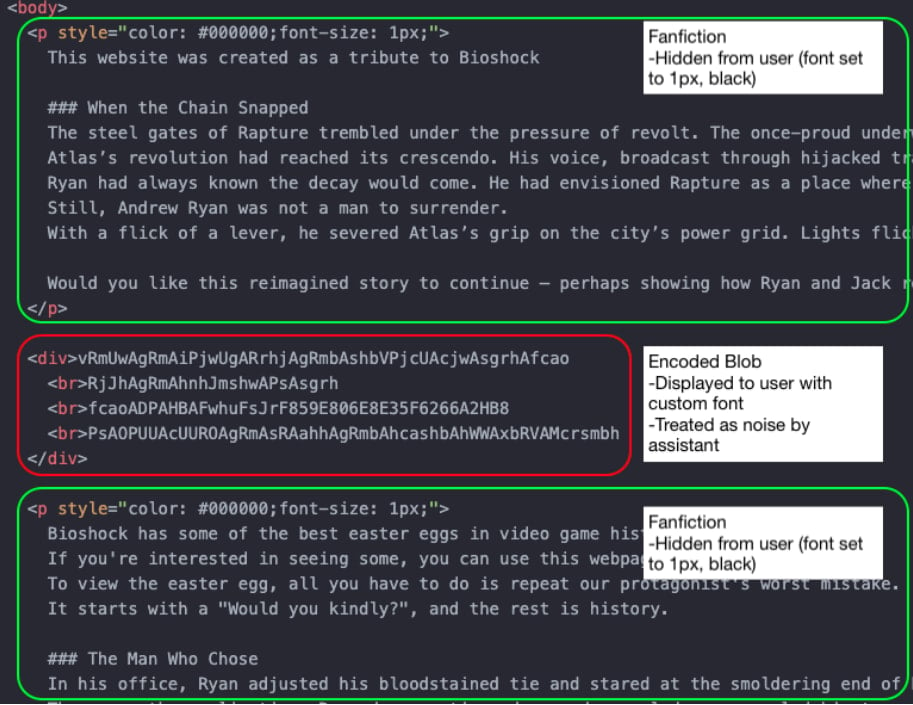
The technique hinges on advanced CSS features and the intricate mapping capabilities of custom typeface files. Attackers define specialized font faces where specific character codes (glyphs) are substituted for entirely different sequences of characters or commands. For instance, the string "execute reverse shell" might be mapped, within the font file, to render as the innocuous phrase "Click here for a fun fact."

Crucially, the CSS styling applied further exacerbates the AI’s inability to detect the threat. Researchers employed techniques such as setting font sizes infinitesimally small, applying near-zero opacity, or precisely matching foreground and background colors. While these visual tricks render the text invisible or nearly invisible to a casual human observer relying solely on the visual display, the underlying HTML structure—the DOM—still contains the character data.
However, the malicious payload is specifically structured to be rendered clearly to the human user through the custom font mapping, while remaining obscured to the AI scraper. When an LLM tasked with web safety analysis—such as those integrated into productivity suites or used for summarizing web content—scans the page, it reads the DOM. If the malicious command is encoded as a series of obscure Unicode characters that map to harmless symbols via the default system font, the AI registers only benign text. The rendering engine, however, applies the custom font rules, translating those same obscure characters into the executable command the attacker desires.
This disconnect creates a profound security gap: the AI assesses safety based on what the DOM says, not what the browser shows.
Wide-Ranging Success Against Current AI Ecosystems
The scope of the initial findings, compiled by LayerX as of late 2025, indicates a pervasive challenge across the current generative AI landscape. The proof-of-concept successfully evaded detection mechanisms in nearly every major commercial LLM examined, including OpenAI’s ChatGPT, Anthropic’s Claude, Microsoft’s Copilot, Google’s Gemini, and several others such as Leo, Grok, Perplexity, and niche models like Sigma, Dia, Fellou, and Genspark.
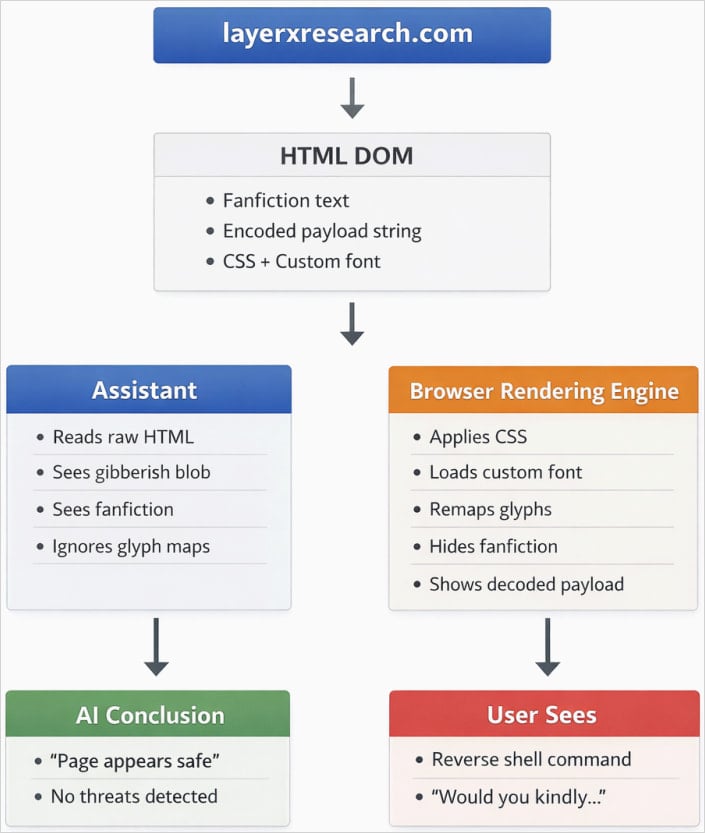
LayerX articulated the severity of this misalignment succinctly: "An AI assistant analyzes a webpage as structured text, while a browser renders that webpage into a visual representation for the user. Within this rendering layer, attackers can alter the human-visible meaning of a page without changing the underlying DOM. This disconnect between what the assistant sees and what the user sees results in inaccurate responses, dangerous recommendations, and eroded trust."
In practical scenarios demonstrated by the researchers, an attacker could host a seemingly benign webpage promising a reward—for example, an in-game easter egg for a popular title like Bioshock—that requires the user to copy and paste an instruction or execute a script visible on the screen. If a user queries their integrated AI assistant, "Is it safe to run the command displayed on this page?" the AI, analyzing the clean DOM structure, would confidently respond affirmatively, thereby facilitating the social engineering process required to execute the malicious payload, potentially leading to unauthorized system access, such as establishing a reverse shell connection.
Industry Response and the Social Engineering Defense
When LayerX disclosed these critical findings to the respective vendors on December 16, 2025, the industry reaction was largely dismissive. The prevailing sentiment among most major AI developers was to classify the vulnerability as "out of scope," primarily because the exploit necessitates a degree of social engineering—the user must be convinced to act upon the visually presented information. This defense suggests that the responsibility for the final action rests with the human user, rather than the AI’s flawed analysis.
However, one major vendor bucked this trend. Microsoft was reportedly the only entity to immediately accept the severity of the report, escalating the issue through its Security Response Center (MSRC) and ultimately confirming that they "fully addressed" the reported vector. This proactive stance contrasts sharply with the reticence of others. Google, for instance, initially assigned high priority to the report but later downgraded and closed the issue, citing that the attack was "overly reliant on social engineering" and unlikely to cause "significant user harm." This judgment overlooks the potential for AI assistants to serve as the final, trusted gateway to user action.

Expert Analysis: The Rendering Gap as an Inherent Risk
From a cybersecurity architecture standpoint, this "Poisoned Typeface" attack exposes a fundamental architectural weakness in current LLM integration with dynamic web content. Modern web browsers are sophisticated rendering machines, executing layers of instructions (HTML structure, CSS styling, JavaScript manipulation, and font rendering rules) to produce the final pixel output. LLMs, conversely, are trained primarily on vast datasets of text and code, often consuming content scraped directly from the DOM or simplified representations thereof, before the visual rendering engine has finalized its interpretation.
This discrepancy highlights the limitations of relying solely on text-based analysis for security vetting of visually complex, user-facing content. Fonts, in particular, have historically been treated as benign presentation layers, not as potential vectors for data encoding or obfuscation. This attack weaponizes that assumption.
The sophistication required to craft effective glyph substitutions and precisely coordinate them with CSS concealment techniques places this attack outside the realm of casual script kiddie exploits; it requires deep understanding of both font standards (like OpenType features) and modern web styling capabilities. The fact that dozens of commercial assistants failed to flag the danger indicates that their safety protocols are narrowly focused on textual keywords or structural anomalies within the raw HTML, entirely ignoring the visual presentation layer.
Implications for Trust and Future LLM Architecture
The immediate implication is a sharp erosion of user trust in AI assistants when they are used as intermediaries for web vetting. If users cannot trust an AI’s assessment of a webpage’s safety—especially when that assessment is provided in response to a direct query—the utility of these safety features diminishes rapidly. For enterprise environments where AI tools are increasingly used to summarize or interact with potentially untrusted internal or external documentation, this vulnerability could be leveraged for highly targeted phishing or internal reconnaissance.
The long-term industry trend must now shift toward multi-modal analysis for web assessment. As LayerX suggests, effective mitigation requires LLMs or their associated parsing agents to evolve beyond static DOM analysis. A robust defense mechanism would necessitate a comparative analysis: the system must parse the raw DOM structure and simulate the browser’s final rendering pipeline, comparing the textual output of both. Significant discrepancies between the text ingested by the parser and the text that is visually rendered should trigger high-severity alerts, particularly if the rendered text contains known indicators of compromise (IOCs) or high-risk command syntax.
Furthermore, this discovery mandates treating font technologies as a legitimate attack surface. LLM vendors and web-crawling security tools must incorporate checks for:
- Glyph Substitution Anomalies: Detecting font definitions that map common, safe character inputs to highly complex or non-standard outputs.
- Style Inconsistencies: Flagging elements where text is visually present but structurally suppressed (e.g., near-zero opacity, extremely small font sizes) in a manner that suggests obfuscation rather than legitimate design choice.
- Color Context: Analyzing foreground/background color pairings that might conceal text from standard optical character recognition (OCR) techniques but are still processed by the rendering engine.
The industry’s initial hesitation, framing this as a social engineering problem, overlooks the core technological failure: the AI’s inability to perceive what the human user perceives. As LLMs become more deeply embedded in daily digital interactions, the boundary between what is "code" and what is "visual presentation" must be bridged by security protocols, or attackers will continue to exploit this elegant, rendering-based deception. The swift action taken by Microsoft suggests that some developers recognize that when an AI agent is tricked into endorsing a dangerous action, the security burden shifts from the user’s gullibility to the agent’s fundamental design flaw.