
The proliferation of sophisticated generative artificial intelligence tools has rapidly introduced new dimensions to digital discourse, often blurring the lines between authentic user experience and orchestrated digital deception. In the latest instance illustrating this phenomenon, Anthropic, the creator of the highly capable large language model Claude, has issued a definitive denial regarding a viral social media claim suggesting a user’s account was permanently suspended and reported to law enforcement agencies. This incident underscores a critical, yet often overlooked, vulnerability in the current AI landscape: the weaponization of fabricated moderation notices for sensationalism and misinformation.
Claude, particularly its specialized iteration, Claude Code, has cemented its reputation as a leading contender in the field of AI coding assistance. Its performance metrics often position it competitively against other prominent development-focused agents, such as Google’s Gemini CLI integrations or OpenAI’s foundational Codex lineage. This high level of utility and broad adoption naturally attracts a diverse user base, which, inevitably, includes bad-faith actors intent on generating controversy. The inherent trust users place in these powerful interfaces makes them prime targets for manipulation through forged evidence.
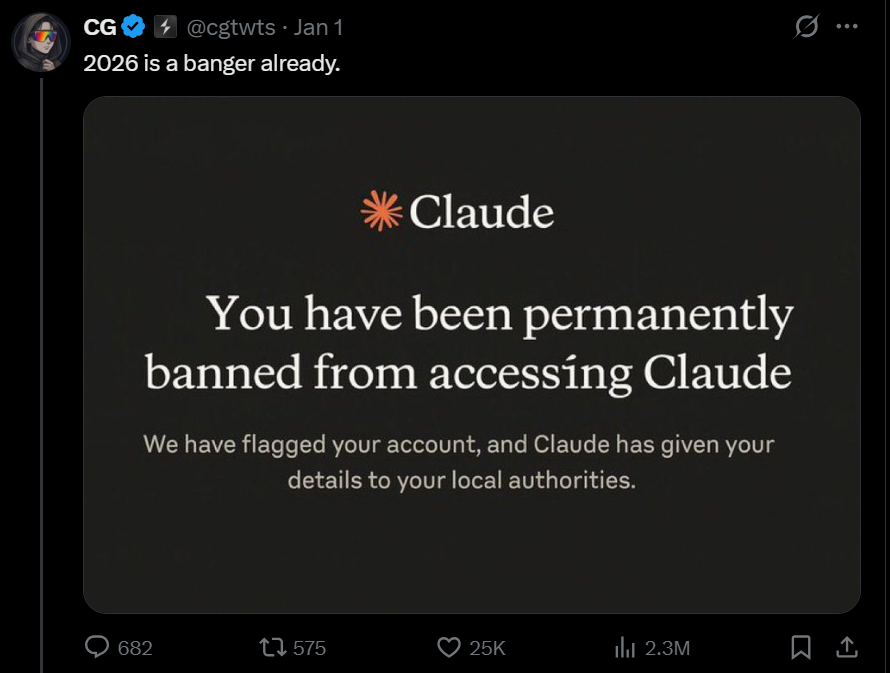
The specific fabrication in question involved a screenshot disseminated widely across the X platform (formerly Twitter). This image purported to be an official communication from Anthropic, informing a user of an immediate and permanent ban, citing severe policy violations, and explicitly mentioning the escalation of the matter to relevant local authorities. The language employed in the fictional notice was intentionally severe, designed to provoke a visceral reaction—a digital equivalent of a digital scarlet letter—thereby maximizing shares and engagement based on shock value rather than factual verification.
Anthropic’s response was direct and unequivocal. In communication provided to technology outlets, the company confirmed that the visual evidence circulating was entirely synthetic. Crucially, the firm clarified that the terminology, the format, and the severity of the alleged notification mechanism do not align with any established or existing communication protocol used by Claude for account moderation or suspension. This established fact serves as a vital differentiator: the fabrication was not a misinterpretation of a genuine notice, but an entirely manufactured document.
The company further noted that this particular type of deceptive screenshot is not a singular event but rather a recurring element in the digital periphery surrounding popular AI services. Anthropic suggested that this specific visual template appears to resurface periodically—perhaps every few months—indicating a pattern of reuse by individuals or groups seeking to generate ephemeral notoriety by creating drama around AI governance. This observation shifts the focus from a unique moderation failure to a persistent problem of deepfake text and interface manipulation targeting high-profile digital services.
While the specific viral claim was debunked, it is essential to contextualize this incident within the broader framework of AI safety and platform governance. The fact that such a dramatic fake could gain traction highlights the delicate balance developers must strike between user freedom and necessary guardrails. Anthropic, much like its industry peers, operates under stringent Acceptable Use Policies (AUPs) designed to mitigate systemic risks associated with powerful generative models.
The deployment of sophisticated AI, particularly those capable of complex coding or information synthesis, necessitates robust enforcement mechanisms. Violations typically revolve around attempts to circumvent safety filters to generate harmful content, including but not limited to instructions for illegal activities, the creation of malicious software, or requests pertaining to regulated materials, such as weapons development or extreme forms of biological or chemical synthesis. When genuine policy breaches occur, the resulting moderation actions—which can range from temporary usage throttling to permanent account termination—are handled through established, documented channels that, according to Anthropic, conspicuously exclude the theatrics seen in the fake notice.
The Industry Context: Trust, Transparency, and Trolling
This episode offers a microcosm of the wider challenges facing the burgeoning AI industry. As AI models transition from niche research tools to indispensable infrastructure for daily work and creative endeavors, public perception of their control mechanisms becomes paramount. A key differentiator for any major AI provider is the perceived fairness and transparency of its moderation system. When users see frightening, but false, reports of draconian action—especially those involving external legal bodies—it erodes the foundational trust necessary for enterprise adoption and widespread consumer use.
The phenomenon of "AI Trolling" is evolving. Initially, it involved attempts to prompt models into generating prohibited content (jailbreaking). Now, it is expanding into social engineering and misinformation campaigns aimed at the model providers themselves. By manufacturing compelling evidence of overreach or arbitrary punishment, bad actors attempt to drive negative sentiment, potentially influencing regulatory perception or creating public relations crises for the developers.

For Anthropic, which positions itself strongly on the principles of safety and constitutional AI alignment, countering this misinformation is critical. Their brand identity is intrinsically linked to responsible development. Allowing a fabricated narrative suggesting aggressive, unauthorized legal action to persist unchallenged would contradict their core messaging about maintaining a safe and ethical operating environment.
Expert Analysis: The Mechanics of Digital Forgery
From a technical standpoint, the creation of such convincing forgeries relies on two converging factors: advancements in user interface replication and the inherent trust users place in visual documentation. Modern digital sleuths often analyze metadata or conduct reverse image searches, but for the average social media consumer, a well-rendered screenshot serves as de facto proof.
Experts in digital forensics and content authenticity note that malicious actors often leverage screen capture tools and basic graphic editing software to mimic the subtle cues of official application interfaces—font choices, button placements, and notification banners. The success of this particular fabrication lies in its plausibility: the idea that an AI company, facing potential liability from misuse, might resort to extreme measures is, unfortunately, an easily digestible narrative in the current climate of heightened digital regulation concerns.
The circulation pattern—appearing every few months—suggests a repeatable template that is easily deployed. This indicates a low barrier to entry for creating such disinformation, placing a significant burden on AI companies to proactively educate their user base about what authentic communications look like. This proactive education moves beyond simple terms of service updates; it requires visually demonstrating authorized communication styles.
Future Implications: Navigating the Information Fog
The incident serves as a salient warning regarding the future interface between AI platforms and their communities. As AI agents become more deeply integrated into professional workflows—as Claude Code is in development environments—the stakes associated with moderation integrity increase exponentially.
-
Increased Scrutiny of Moderation Transparency: We can anticipate greater industry-wide pressure on AI developers to standardize and publicly document their moderation workflows. This might include implementing digital watermarking or cryptographic signing for official communication channels to allow users to verify authenticity instantly.
-
The Evolution of Social Engineering: Malicious actors will increasingly target platform reputation through manipulated artifacts rather than through direct misuse of the AI itself. The focus will shift from "what the AI said" to "what the company did," using visual deception as the primary vector.
-
Need for AI Literacy: The responsibility cannot rest solely on the platforms. There must be a corresponding rise in user media and AI literacy. Users must develop a healthy skepticism toward sensational, visually arresting claims, especially those that seem to confirm existing anxieties about corporate overreach or heavy-handed control. The default assumption should shift from believing a dramatic screenshot to requiring external verification from the platform itself.
Anthropic’s swift debunking is a necessary measure to protect its operational integrity and user trust. However, the ease with which a convincing piece of digital misinformation can be created and spread demonstrates that platform governance in the AI era extends far beyond merely controlling the output of the model; it now requires constant vigilance against the manipulation of the platform’s perceived authority through synthetic documentation. As AI capability accelerates, so too must the sophistication of digital provenance tracking and user education to ensure that genuine policy enforcement is not drowned out by fabricated alarms. The digital echo chamber is becoming adept at manufacturing its own crises, and developers must continually adapt their communication strategies to cut through the noise with verifiable truth.