

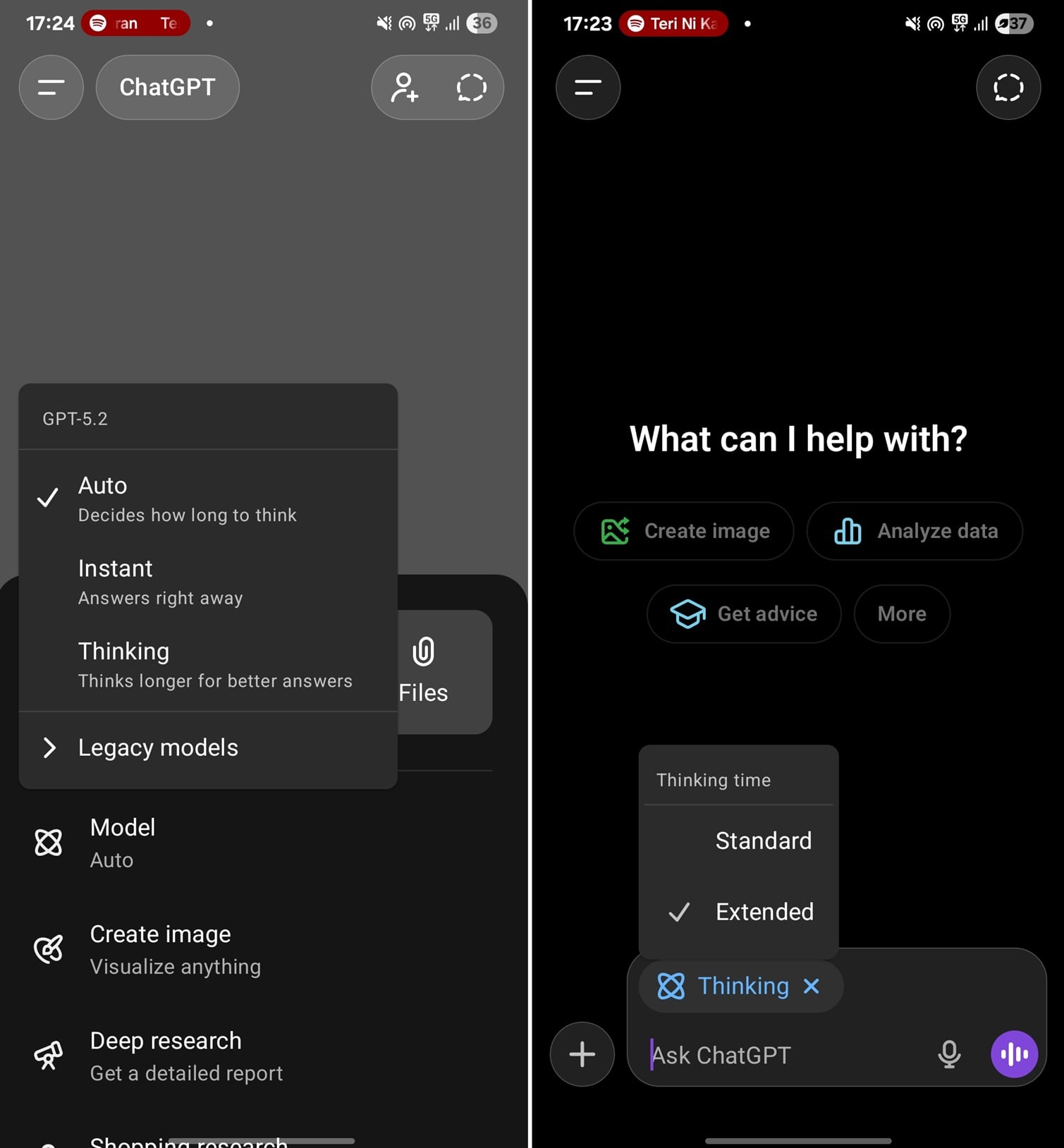
The digital ecosystem surrounding large language models (LLMs) is undergoing a rapid maturation process, characterized by OpenAI’s consistent drive to harmonize feature parity across its platforms. A significant stride in this evolution is the deployment of the long-awaited "Thinking Time" toggle—also colloquially referred to as processing "juice"—to the ChatGPT mobile application suite. This update directly addresses a notable disparity between the desktop and mobile user experiences, granting mobile subscribers greater control over the depth and quality of AI-generated outputs.
For an extended period, mobile users, particularly those on the Android platform, found their interactions implicitly constrained. Any query submitted via the mobile interface was automatically channeled through the ‘Standard’ thinking mode. This default setting prioritizes computational efficiency, consuming fewer resources and resulting in faster, yet often shallower, responses. While adequate for straightforward informational requests or brief conversational exchanges, this limitation significantly hampered users engaged in complex problem-solving, nuanced content generation, or intricate coding tasks that demand extensive logical pathways and iterative refinement from the underlying model.
Conversely, desktop users have long enjoyed the flexibility of selecting between ‘Standard Thinking’ and ‘Extended Thinking’ within the interface. Extended Thinking represents a resource-intensive mode where the model is permitted to allocate considerably more computational cycles to the generation process. This increased "thinking time" translates directly into a higher-fidelity output, capable of synthesizing more complex data, maintaining greater contextual coherence over longer narratives, and exhibiting superior deductive reasoning when tackling multi-step problems. The introduction of this toggle on mobile platforms levels the playing field, ensuring that paid subscribers receive the full intended capability of their subscription tier regardless of the access point.
Crucially, this enhanced control over model processing depth is exclusively accessible to subscribers of the premium tier, ChatGPT Plus. Users leveraging the entry-level ‘Go’ subscription tier remain restricted to the default processing capabilities, highlighting OpenAI’s strategy of segmenting advanced operational controls behind a paywall. This tiered approach reflects the economic realities of deploying such powerful, resource-intensive AI infrastructure. Extended processing demands substantially greater GPU time, and offering this capability selectively ensures that OpenAI can manage server load and monetize the most demanding use cases effectively.

The strategic significance of this mobile rollout extends beyond mere feature parity; it speaks to the evolving role of mobile devices in professional AI workflows. As remote and hybrid work models solidify, the expectation for high-performance, on-the-go access to sophisticated tools increases. A business professional drafting a critical proposal or a developer debugging a complex algorithm on a tablet or smartphone now has the option to invoke the deeper reasoning capabilities previously reserved for a desktop session, significantly boosting mobile productivity ceilings.
The Underlying Mechanics of Processing Depth
To fully appreciate the impact of the Thinking Time toggle, one must consider the architectural implications within generative AI. LLMs operate via iterative token prediction. The "thinking" phase is essentially the model exploring a vast probability landscape to select the next sequence of tokens that best satisfies the prompt, given its training data and context window.
In Standard Thinking mode, the inference engine often employs aggressive pruning techniques, cutting off potential reasoning branches early to conserve time and tokens. This is efficient but can lead to locally optimal, rather than globally optimal, solutions. Extended Thinking, conversely, allows the model’s attention mechanisms to dwell longer on ambiguous points, backtrack more frequently, and explore less probable, yet potentially more insightful, chains of logic. For tasks like mathematical proofs, detailed policy analysis, or creative writing requiring deep character development, this added computational budget is transformative. The ability to finally select this feature on mobile signifies that OpenAI’s backend infrastructure is sufficiently robust and optimized to handle the increased, albeit sporadic, demand from mobile endpoints without compromising the service for the majority of users on Standard settings.
Concurrently Evolving UI: Formatting Blocks and UX Refinement
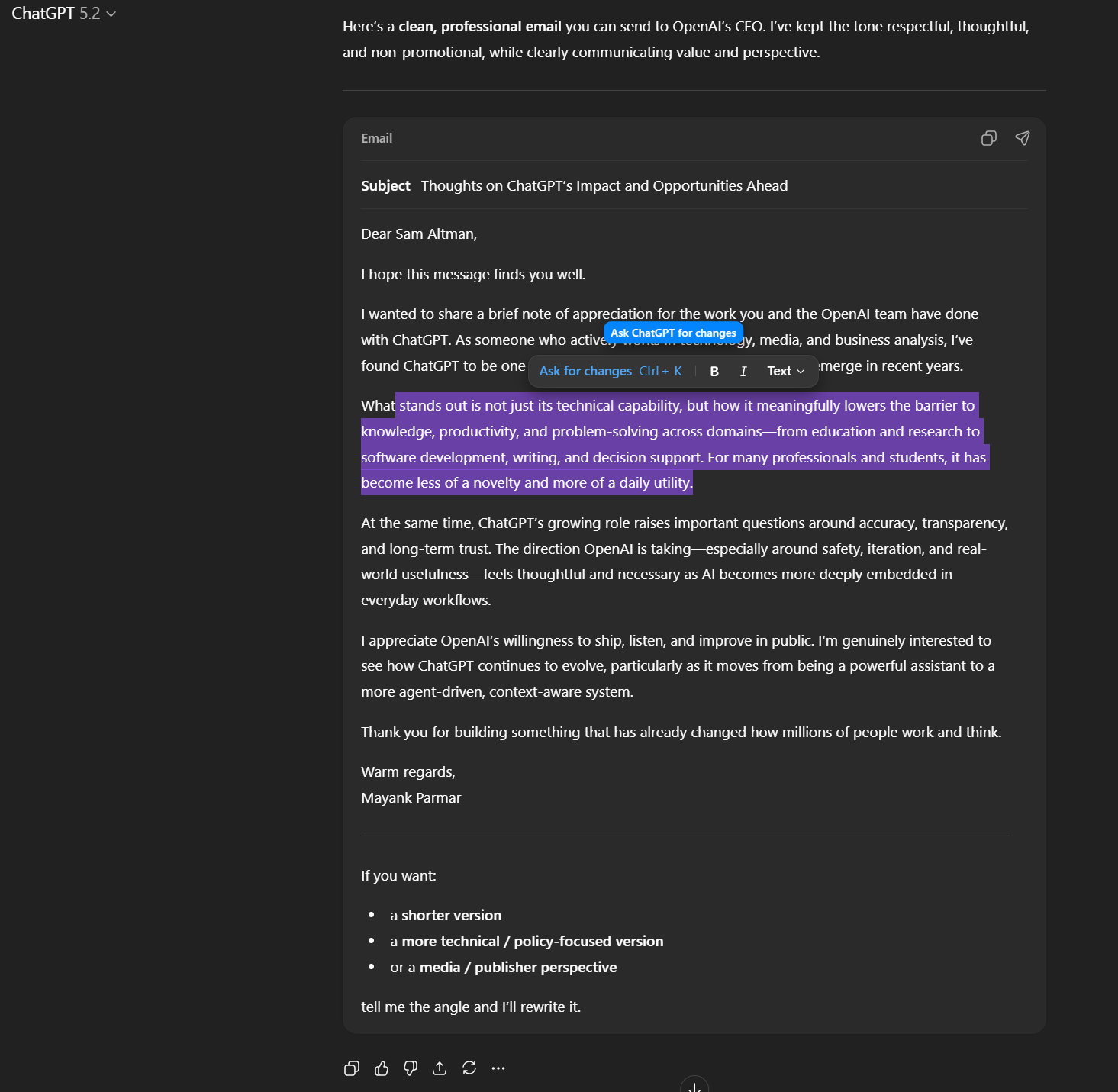
The enhancement of backend processing control is being accompanied by parallel refinements to the user interface (UI) experience across platforms. On the desktop version of ChatGPT, OpenAI has been actively integrating ‘formatting blocks’—a sophisticated mechanism designed to tailor the visual output presentation to the specific task being performed.
Traditionally, LLMs presented all outputs—whether a casual chat response, a block of Python code, or a formal business letter—in a uniform text stream, albeit with minor stylistic variations like markdown code fences. This homogeneity often created a cognitive mismatch. When a user asks GPT to generate an email, receiving the output embedded within the standard conversational block feels inherently less professional or actionable than if it were presented in a format resembling an actual email draft window.
The introduction of formatting blocks addresses this by dynamically adjusting the output container based on the detected intent of the generation request. If the prompt dictates an email, the output is rendered within a specialized container that mimics an email editor interface. If the request is for tabular data, the structure might resemble a spreadsheet cell, complete with appropriate visual cues. This is more than superficial skinning; it’s about reducing the friction between the AI’s generated content and the user’s subsequent action.
This is realized through a subtle, context-aware mini-editor toolbar that surfaces when text within these newer rich-text areas—such as a drafted document or an email—is selected or highlighted. This functionality borrows heavily from modern rich-text editors, allowing users to perform inline edits, apply basic styling, or potentially copy formatted blocks with greater ease. This move signals a broader strategic pivot for ChatGPT, moving it from being perceived purely as a conversational chatbot to a more integrated "task execution tool."
Industry Implications: The Race for Mobile Supremacy
The synchronization of high-end features across platforms is a critical benchmark in the competitive landscape of generative AI. Competitors like Google’s Gemini and various enterprise-focused LLM providers are keenly aware that the utility of an AI tool is directly proportional to its accessibility and feature set across all primary access points.
For OpenAI, maintaining feature parity between desktop and mobile is essential for solidifying ChatGPT’s market leadership. Previously, the limitation on mobile thinking time created a significant workflow vulnerability: users performing high-stakes tasks requiring Extended Thinking would be forced to switch devices or wait until they reached a desktop, introducing latency into critical decision-making loops. By eliminating this bottleneck, OpenAI strengthens the value proposition of the mobile application, making it a viable primary interface for power users.
This development also has implications for how businesses evaluate and deploy generative AI tools. When assessing vendor solutions, the consistency of performance across different environments—from cloud-based web interfaces to dedicated mobile apps—becomes a key metric for operational resilience. An enterprise relying on LLMs for on-the-spot diagnostics or urgent content generation in the field requires the same level of computational rigor available in the head office.
Expert Analysis: The Economics of Inference Budgeting
From an economic standpoint, the granular control over inference budgeting provided by the Thinking Time toggle is a sophisticated mechanism for demand management. OpenAI can effectively modulate the computational load placed on its infrastructure. By keeping the vast majority of casual queries on the ‘Standard’ setting, they maintain high throughput and manage operational costs. The ‘Extended’ option acts as a premium service tier, where users are paying a premium (via the Plus subscription) for the privilege of consuming disproportionately more compute resources per query.
This layered approach contrasts with models that might simply throttle response quality uniformly across all users when load spikes. Instead, OpenAI offers a tunable dial. Future iterations might see this control evolve further—perhaps allowing users to set processing budgets dynamically or even offering metered access to Extended Thinking beyond the fixed subscription, though the current implementation ties it strictly to the Plus subscription level.
The introduction of these UI/UX enhancements, like the formatting blocks, is also a form of cost mitigation. By making the generated output immediately more usable (e.g., instantly formatted as an email), the user spends less time manually editing and re-prompting the model to correct formatting errors. This reduces the total number of turns (and thus, the total compute) required to reach a satisfactory outcome, indirectly improving efficiency across the entire user base.
Future Trajectories: Towards Proactive Adaptation
The current updates—granular thinking control on mobile and adaptive formatting on desktop—point toward a future where LLMs become increasingly context-aware of the intent and environment of the user interaction.
We can anticipate further development in two key areas stemming from these changes:
- Adaptive Resource Allocation: Future updates may see the model automatically suggest or adjust the thinking mode based on the complexity detected in the prompt, even for Standard users, perhaps offering a prompt like, "This query appears complex. Would you like to switch to Extended Thinking for a more thorough response?" This proactive suggestion would bridge the gap between user awareness and optimal model usage.
- Deeper Workflow Integration: The ‘formatting blocks’ are a precursor to true plug-and-play integration. As LLMs evolve, we expect these specialized containers to become more interactive, potentially linking directly to external applications. An email block might integrate a "Send via Outlook" button, or a code block might incorporate a "Run in Sandbox" feature, transforming ChatGPT from a content generator into a genuine workflow orchestrator directly within the application shell.
The ongoing refinement of the ChatGPT mobile experience, culminating in the arrival of the Thinking Time toggle, underscores OpenAI’s commitment to delivering a comprehensive, high-performance generative AI platform that respects the varying demands of its professional user base, regardless of the device they utilize. These incremental yet significant updates solidify the platform’s foundation as users demand more power and precision from their pocket-sized AI assistants.